If you are interested in information retrieval, you probably hear a lot about semantic search these days. However, semantic search is not really a new topic. It has been around for at least 20 years. According to Wikipedia, semantic search denotes search with meaning, as distinguished from lexical search where the search engine looks for literal matches of the query words or variants of them, without understanding the overall meaning of the query. Semantic search is generally considered as Artificial Intelligence (AI).
Since the beginning of AI there have been two mainstream approaches, symbolic methods such as expert systems and machine learning methods such as neural networks and the focus constantly moved between these two directions. Nowadays everybody is excited about large language models (Transformers and ChatGPT) and about using them for semantic search. But until about 5 years ago, semantic search was usually a synonym for so called semantic web technology, such as thesauri and ontologies, which are symbolic AI techniques. In this blog article I will give an overview over AI technologies for semantic search and point out on what we are currently working at IntraFind.
Traditional full text search
Let’s first have a closer look at traditional full text or lexical search. Documents and queries are represented according to the bag-of-words vector space model (see Figure 1). In this vector space, each word spans one dimension of the vector space. Queries are treated simply as short documents.
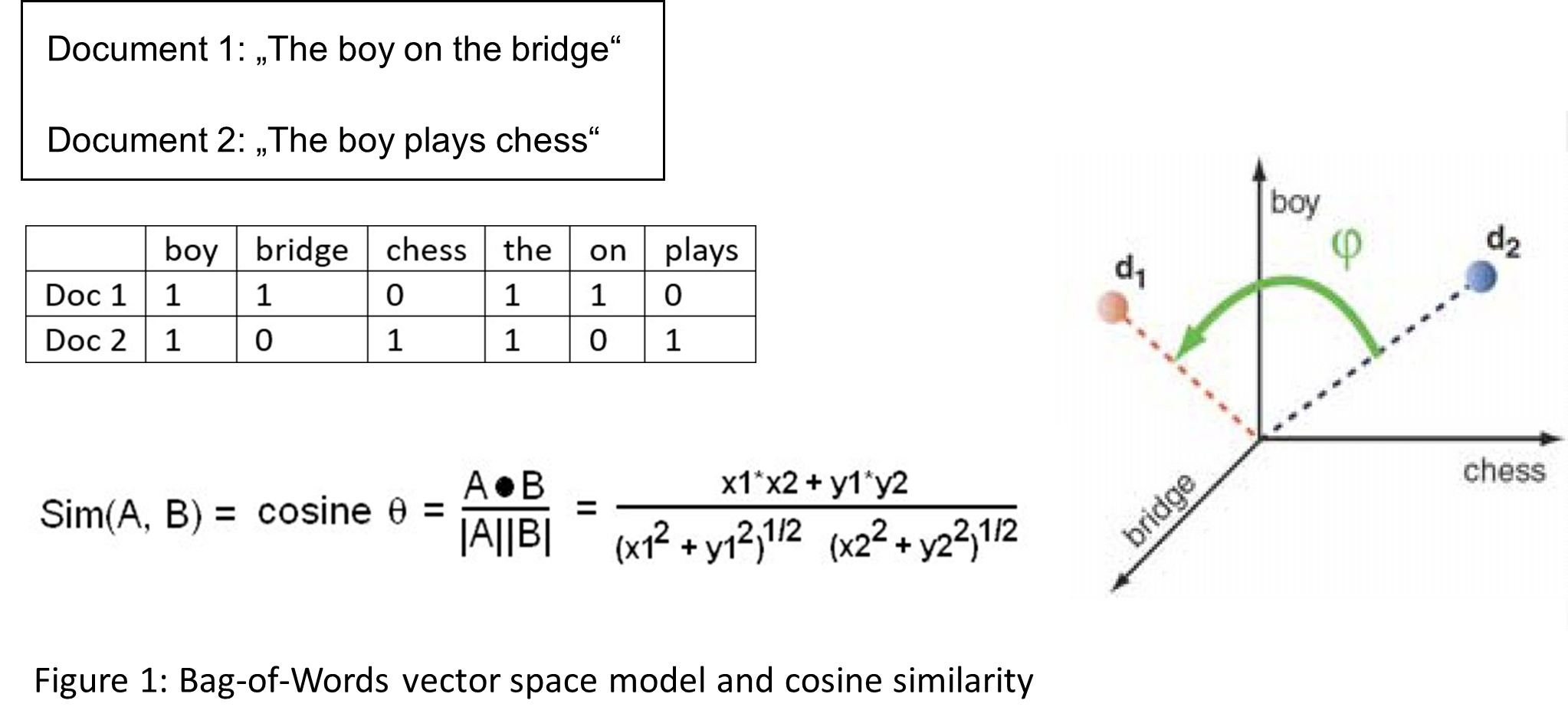
Similarity between a query and documents is measured by the cosine similarity (length-normalized dot-product) between the query and the document vectors. So basically, the angle between these 2 vectors is used to measure similarity and to score documents. The bag-of-words vector space typically has a very high dimension (one dimension for each word in any document). If you consider that this includes artificially generated identifiers, (product) numbers, dates, error codes etc., the dimension may be in the millions for big search engines. Each document contains only a small number of words, so the actual vectors are sparse.
The big advantage of this model is that there is a data structure (inverted file index) that allows to compute the dot product of a query very efficiently with millions or billions of document vectors making use of the sparseness, that basically allows to skip most of the documents if they contain no or very few of the query words. This data structure is the foundation for traditional search engines, e.g. for Lucene, Elasticsearch, and OpenSearch.

Figure 2: Problems with the bag-of-words model
However, traditional full text search has several weaknesses. Figure 2 demonstrates some of them. First, there is the vocabulary mismatch problem, which refers to the problem that a query and a document won’t match if they use different words to describe the same concept. Furthermore, the bag-of-words model ignores the meaning of words, e.g. it is unable to distinguish between the adjective live in live music and the verb live in many people live in Rome and it ignores the order of words (see 2 sentences about policemen and muggers). Note however, that usually the inverted file index also stores positions of words / tokens so that it is possible to search for multiword phrases such as New York and specify that search terms must occur at a maximum distance from each other. Semantic search tries to overcome the weaknesses of traditional full text search.
Symbolic AI for Semantic Search
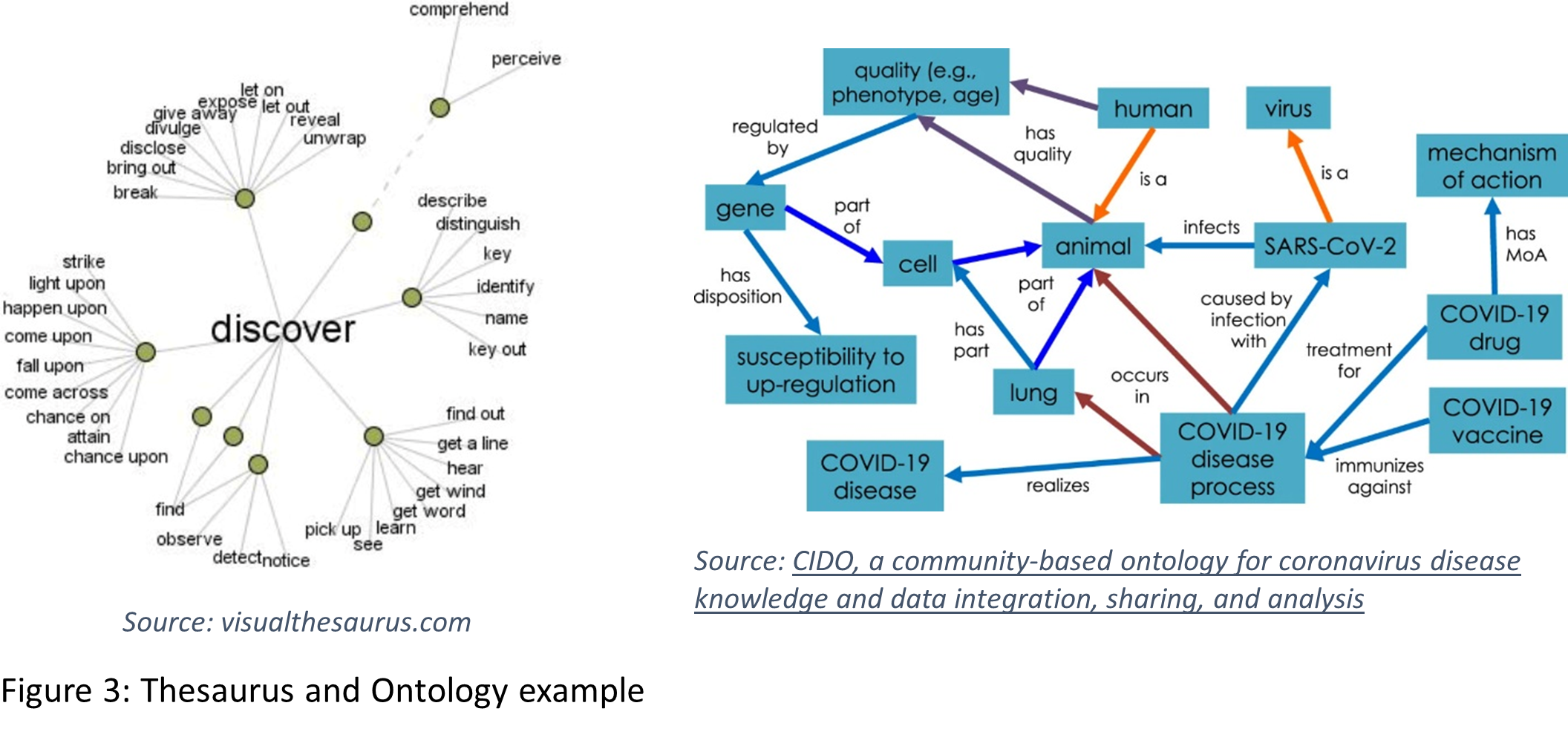
At IntraFind we have a long tradition of using symbolic AI techniques for semantic search. Especially, we tackle the vocabulary mismatch problem by using high-quality lemmatization and word decomposition for 30 languages and with the integration of thesaurus resources for query expansion. See also our blog article New High Quality Search and Linguistics for iFinder5 elastic. Figure 3 shows parts of a thesaurus and of an ontology, that could be used for semantic search.
Besides these approaches we have implemented the typed index that allows us to integrate arbitrary components for named entity recognition (NER) and generate something that we call a semantic index. Note that by using transformer-based NER components, this constitutes a hybrid approach that combines symbolic AI and neural networks. Together with a powerful query syntax, this allows question answering.

Figure 4 shows typical questions, how they translate into our query syntax and the kind of answers we get. The Near-operator allows us to specify a maximum token distance within a document, ENTITY/PERS and ENTITY/ORG represent arbitrary persons and organizations respectively, and the UNIT-operator allows to specify queries concerning units such as temperature, length, power, amounts of money, … . Off course this query syntax is something that is used mainly by search experts. However, we are working on methods to automatically translate natural language queries into this syntax.
Large Language Models for Semantic Search
Cross-Encoder
In 2017 the paper “Attention is all you need” introduced the transformer network architecture. This network architecture consisted of an encoder and a decoder and was used for machine translation. In the following years it turned out that the encoder part can be used for various NLP tasks such as entity recognition, semantic similarity, and information retrieval. The decoder part can be used for language generation, ChatGPT being the most prominent example.
In the following, we focus on using methods to use the encoder part for semantic search. Figure 5 schematically shows architecture and training of encoder networks.
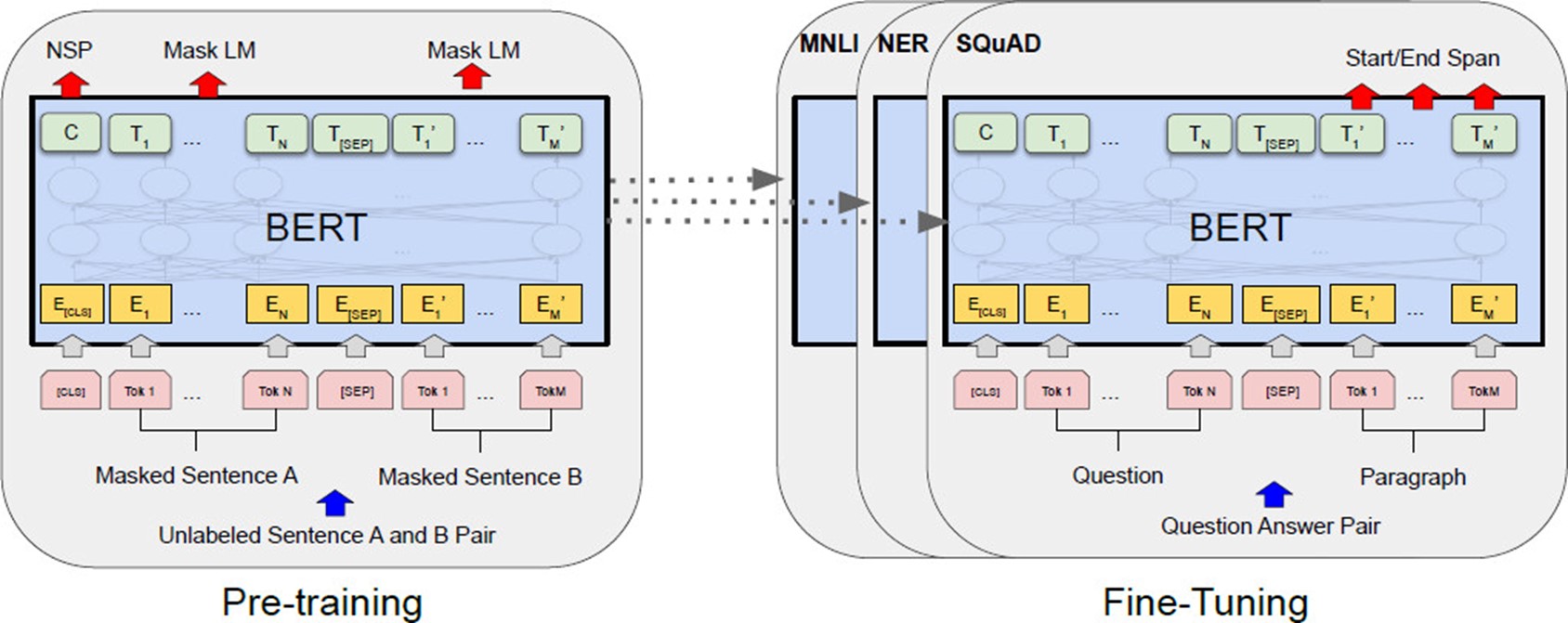
Figure 5: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Transformers are trained in an unsupervised way on the task of predicting the next word (decoder) or on mask token prediction (encoder). This training is called pre-training and it can be done using an arbitrary (usually huge) amount of text. Pre-training gives the language model a basic understanding of language. Encoders are typically trained on a window of 2 sentences. For specific tasks such as information retrieval, the encoder must be trained in a supervised way using labeled data for that task. This training is called fine-tuning. In case of information retrieval or question answering, pairs of queries and matching passages are needed for fine-tuning. Data labelling is usually done be humans, which is expensive. Recently, generative models have been successfully used to generate labeled data synthetically.
Encoder networks may be used directly to decide if a query and a specific passage match. However, this requires that query and passage are processed by the encoder in parallel side-by-side. This approach to semantic search with language models, which is usually called cross-encoder approach, is quite expensive. Scoring several passages means a linear scan over all these passages and each of the individual operations (processing the query along with a passage) is by itself already quite an expensive operation. Therefore, the cross-encoder approach, while delivering the highest accuracy, can only be used for re-ranking of a small number of candidate passages, that have been retrieved by a less expensive first-stage retriever. The first-stage retriever is usually a traditional search engine, or a dense vector search.
Dense Vector Search
Besides the cross-encoder approach, semantic vector search has been developed to completely replace traditional search. Figure 6 shows the architecture of a bi-encoder. It uses a transformer encoder network like BERT, but query and passages are encoded separately. Either the additional special classification token or a pooling of all output tokens is used to generate an embedding vector for the query and for each passage. The embedding vectors are optimized / trained in such a way that the cosine similarity between queries and passages are high if they match and low if they don't match.
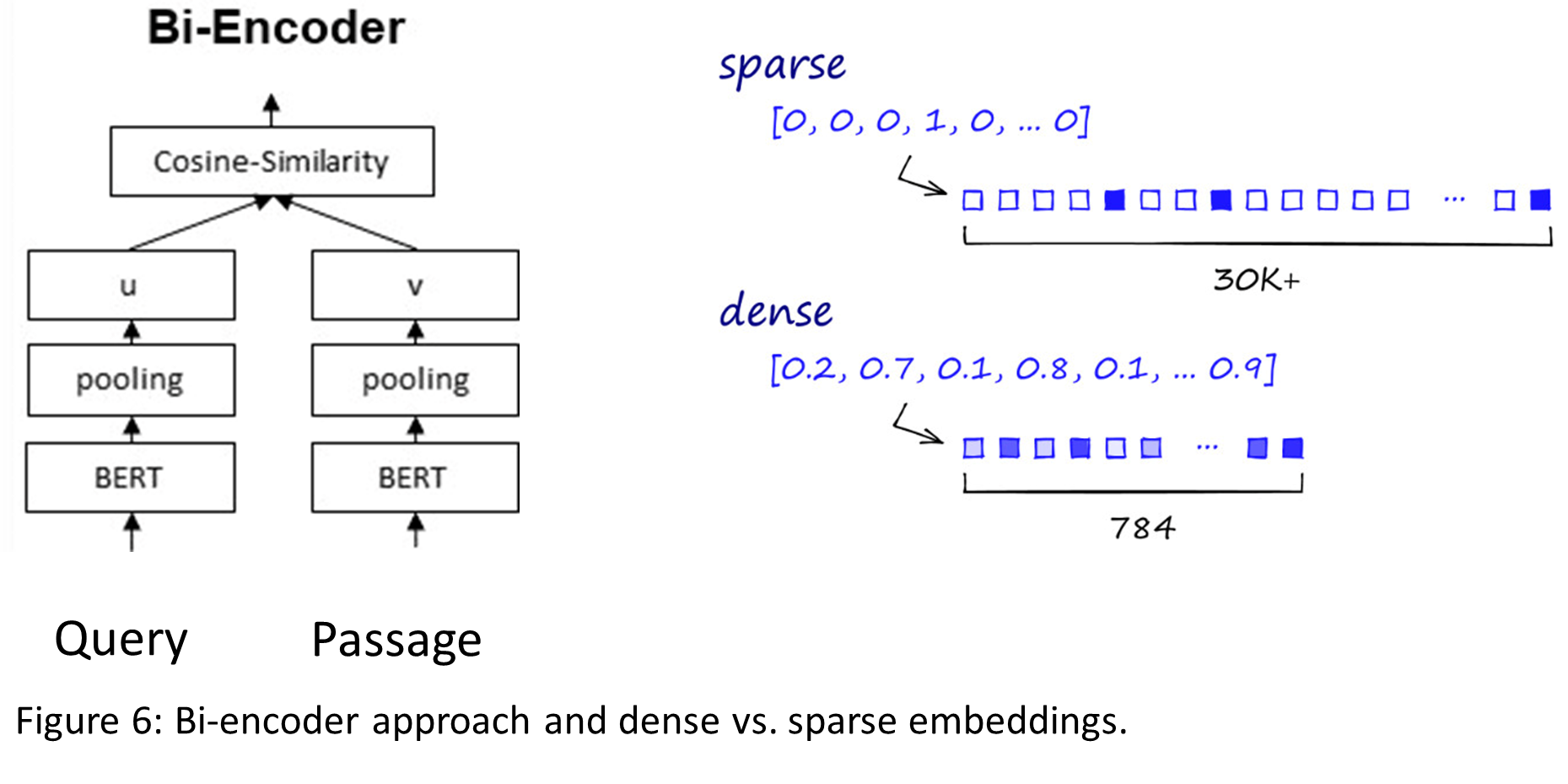
This again means supervised training on labelled data. The passage embedding vectors can then be stored in a database. In contrast to traditional full text search these vectors are dense, and they have a much lower dimension, typically between 100 and 1000. Fortunately, during the last view years, data structures such as HNSW have been developed that allow for a given query vector the retrieval of the most similar vectors without linearly scanning over all passage vectors, and these data structures have already been included into for Lucene, Elasticsearch, and OpenSearch. However, they are not as efficient as traditional full text search, and the results are only approximately correct. Some search results might be missing. The paper BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models showed, that while in-domain accuracy of semantic vector search is impressive, zero-shot performance on domains on which these networks had not been trained was worse than traditional full text search. So, to be used for a specific search application (e.g. search on a customer’s documents) fine-tuning on labeled data for that application might be needed. A big advantage of dense vector search is, that it can be used to implement multi-modal search, which combines search on text an images, maybe even sound and videos.
Problems with Semantic Search based on Large Language Models
Semantic search based on large language models offers impressive accuracy gains over traditional full text search especially if queries are complex (such as question answering). But there are also some serious disadvantages, that currently still prevent widespread use in practical applications.
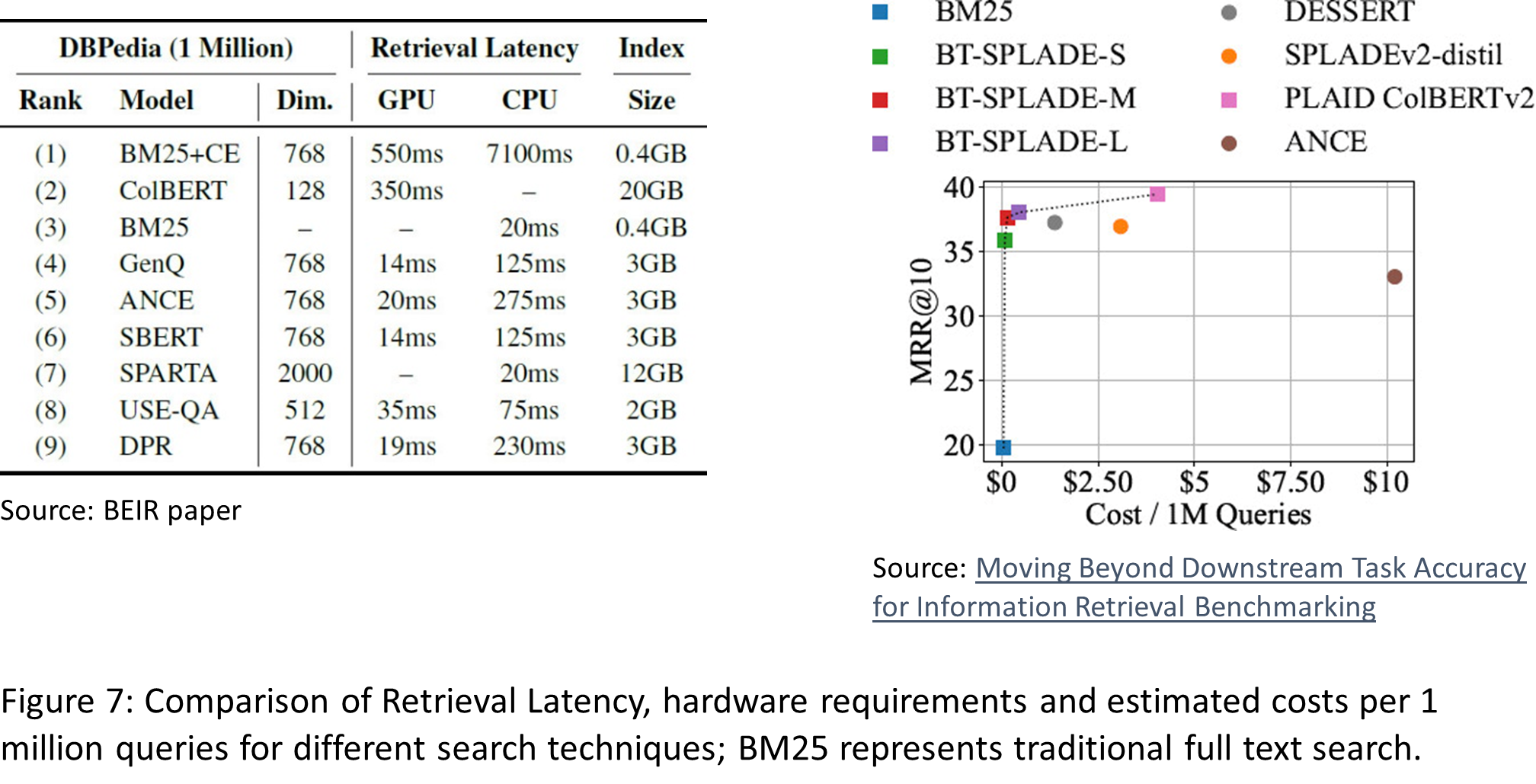
One of the first things that comes into mind are hardware costs. Figure 7 shows that index size may increase by a factor of 10 to 50, query latency may increase by a factor of 10, even if GPUs are used, and costs per 1 million queries may increase by a factor of 10 to 200.
Another disadvantage is the lack of explainability. While traditional full text search and symbolic approaches can easily explain the reason for a match between a query and a passage (see e.g. Figure 4), this is not the case for semantic search based on large language models. There are ways to achieve explainability, however they need another round of fine-tuning of a large language model for answer extraction and labeled data is needed.
The third problem with semantic search based on large language models is that it does not seem to be very robust. It sometimes delivers completely strange results with no explainable relevance. One reason for that is buried deep down in large language models. It is caused by the way they tokenize language. Large language models only allow a fixed vocabulary, typically about 30.000 tokens. These are optimized with respect to the English language. But even for English, many words are split into several tokens that don’t have reasonable meaning by themselves. This is much worse for other languages and for tokens that represent product or error codes. A token like F7GN is split into 4 tokens, one for each letter. Large language models are currently not able to handle simple one-word queries properly, especially if they are out of the domain on which they had been fine-tuned. This not only holds for error or product codes or numbers. Figure 8 shows an example of dense search failing completely when searching for the author Thoreau, a query which traditional full text search can easily answer.

Semantic search based on large language models currently cannot replace traditional full text search. It delivers impressive accuracy gains for complex queries, but not for the high-frequency short queries. It still has to be combined with traditional full text search to guarantee good search results over a broad range of queries.
Hybrid AI Approaches for Semantic Search
At IntraFind we currently focus on hybrid approaches, that combine traditional full text search, symbolic AI methods and large language models for semantic search. Our first approach is described in the blog Word Embeddings: a technology still relevant? It describes how we use word embeddings to generate domain- and customer-specific thesaurus resources and how word embeddings can be used to disambiguate single-word queries.
There are very interesting approaches that generate sparse embedding vectors based on transformers. The idea was first introduced with SparTerm and SPLADE. These approaches currently seem to take the lead if it comes to accuracy and they achieve this with quite moderate hardware requirements. The right part of Figure 7 shows that some SPLADE models deliver high accuracy with low costs. The basic idea is very similar to dense vector search. Again, transformers are used to produce representations for queries and passages separately in a bi-encoder approach. The only difference is that this time the embedding vectors are sparse. The vector space is the space spanned by the tokens produced by the transformer’s tokenizer (dimension typically about 30.000) and a special regularization method is used to make the embedding vectors sparse, meaning, that only a few tokens are allowed to contribute to the match. Figure 9 shows how tokens in passages and queries get weights.
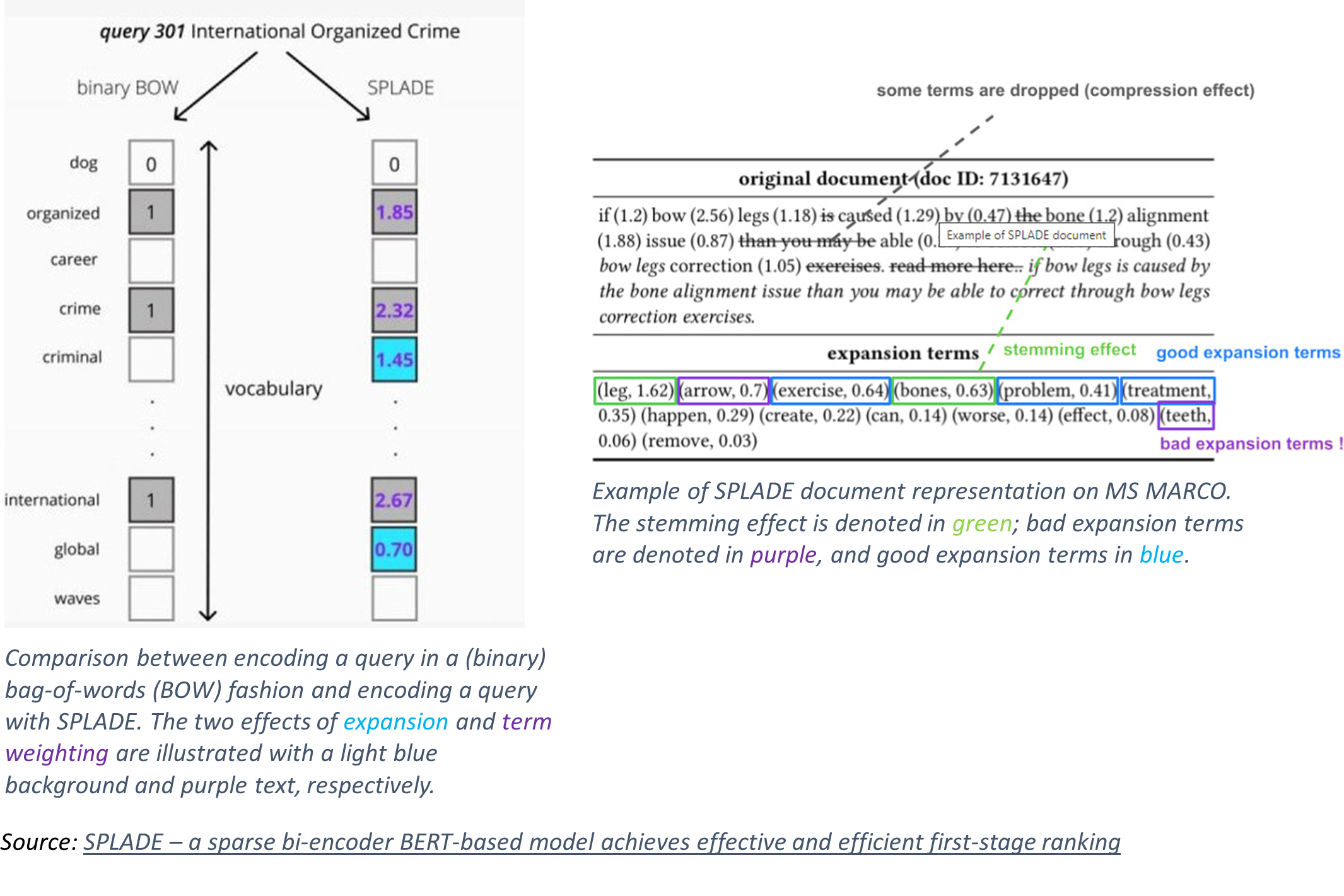
Figure 9: Query and Passage encoding for SPLADE.
Furthermore, based on the context of the passage or query respectively, tokens can be added (context-aware synonym expansion), and some tokens not related to the actual content can be dropped (context-aware stop words). The big advantage of these sparse embeddings is, that with these embeddings, search can be implemented by using the data structures of a traditional search engines (inverted file index). Hardware requirements are quite moderate and search results can be explained with highlighting. We are currently working on our own version of this approach, which combines sparse embeddings with learning to rank approaches and also makes use of our typed index (see Figure 4).
The role of Generative Language Models in Search
Our blog article “ChatGPT: The Future of Search?” already explains why generative models such as chatGPT will not replace search engines any time soon. The main reason is, that they are just language models, meaning that based on the context given to them, they predict the best next token and can be told to continue doing this for quite a while. However, they do not store factual information like a database or a search engine. Therefore, they tend to hallucinate. However, this is just a humanizing interpretation of their behavior caused by the fact that their perfect language makes them seem very human.
No doubt, generative language models will play a major role in search technology in the future. However, their role will probably be restricted to being the interface, that interacts with the user, while the actual results will be delivered by search engines from which the generative models might extract answers. This is the main use case we are currently exploring. Besides that, there are a couple of other use cases. We already mentioned that generative models can be used to generate synthetic passage retrieval data for fine tuning transformers for information retrieval. They might also replace encoder networks for tasks such as named entity recognition or text classification.