ChatGPT: The Future of Search?
Dr. Christoph Goller, Head of Research at search specialist IntraFind, has tried out ChatGPT and thought about its effects on search engines.

There is a lot of excitement about ChatGPT. The technology behind it is based on the decoder part of the original transformer model. Before that, there was a lot of excitement about BERT-like models. Their architecture is based on the encoder part of the transformers. Both have in common that they are trained in an unsupervised way on huge text data, and both are a big step in the direction of general text understanding. They advance the quality of NLP applications considerably. However, I severely doubt whether transformers will replace traditional search engine technology any time soon. For Chat GPT I analyzed this in more detail in a recent blog article. As far as dense retrieval (based on BERT-like encodings) is concerned, I think there are severe problems with hardware requirements (performance), explainability and special vocabulary. Dense retrieval is extremely good for question answering, but what about search for error or product codes. For search based on BERT-like encodings, supervised training on labeled QA data is needed and this seems to imply severe domain-dependency. The results in BEIR show that currently dense retrieval systems trained for a specific benchmark do not outperform the baseline keyword search when we average results over several benchmarks. However, they come with much higher costs.
Are word embeddings - the first deep learning models for text - still relevant? I think as a transitional technology they might well be. Word embeddings constitute a much simpler deep learning model. The goal is to learn / generate embedding vectors for words based on the vectors of their context. Figure 1 shows the architecture of CBOW (continuous bag of words). The training goal for the network is to predict a word based on its context which in Figure 1 is a window of 2 tokens to the left and to the right.In practice a typical window size is 5 to 10. The most important property of word vectors generated in this way is, that words with similar meanings end up with very close embedding vectors. By applying a clustering algorithm, we can generate a special kind of thesaurus where individual entries contain words that are semantically related. Hardware requirements for training word embeddings are quite moderate compared to transformers, so they can easily be trained on customer data.
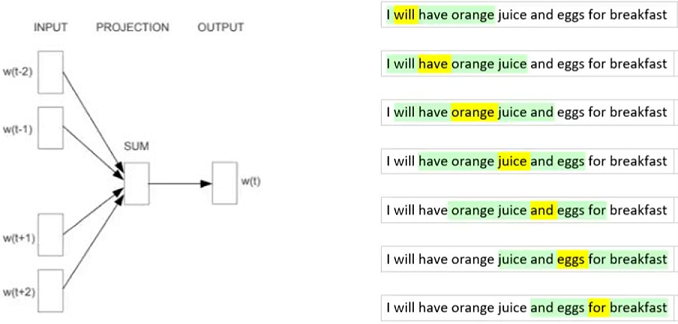
Figure 1: Architecture CBOW
Figure 2 shows some clusters that were generated from word embeddings trained on Wikipedia. There is e.g., a cluster with places in Greece, mostly islands, a cluster with Mexican food, one with soft drink labels, and a cluster comprising the concepts of inventions and patents. There is also a cluster on geolocial eras and one containing medical terms related to the heart.

Figure 2: Some word clusters automatically generated from word embeddings trained on Wikipedia.
A thesaurus based on word embeddings can be used for automatic query expansion. Using the examples from Figure 1, if there are no hits for the query nachos then hits containing buritos might be better than no hits at all. If I am searching for someone who invented the drum brake, someone with a patent for it might be the right answer. Furthermore, we can have clusters with different abstraction levels at the same time, giving us a kind of hierarchical thesaurus. A smaller cluster might contain soft drinks, a more general cluster all kinds of drinks and for query expansion we can apply the highest boost for the smallest clusters matching a query. We successfully applied the same principle to supervised text classification based on the bag-of-words model and simple logistic regression / support vector machines resulting in a semi-supervised training method that can also benefit from unlabeled data.
In summary, word embeddings might be able to solve the vocabulary mismatch problem[1] for information retrieval in a way very similar to dense retrieval but with much lower costs. Their big advantage is that they fit perfectly into the bag-of-words model of traditional information retrieval systems and in contrast to transformers they are not a black box. The behavior of search based on these thesaurus-resources is perfectly explainable.
We often have single word (or multiword phrase) queries. Someone might e.g., be searching for Munich. In traditional keyword search, a short document containing Munich or a longer one which contains Munich several times will get a high score. But such documents are not necessarily the best answers. Word embeddings can give us words that occur typically close to a given word, e.g., the query. For the query Munich these might be words like beer, Oktoberfest, Bavaria, soccer, Marienplatz, etc. We can use this for boosting documents that contain lots of these typical context words. These documents will be more relevant hits since they most likely contain information about Munich and do not just mention it by accident.
Single word queries might sometimes be ambiguous. We all know ambiguous words such as bank that may identify a place to sit on or a financial institution. However, ambiguity is actually corpus specific. If we build a search engine for a financial institution, we probably don’t have to deal with the ambiguity of the word bank. If we handle documents for a pharmaceutical lab, the word mouse is probably not very ambiguous. It always refers to the animal. In general text it might also refer to a computer mouse. We recently tested an approach where we apply a clustering algorithm to the contexts of a word. It seems that (as expected) words with very inhomogeneous contexts lead to more distinctive clusters and that these clusters can even be used to produce descriptions for the different meanings of these words. We did this evaluation on word embeddings trained on the German Wikipedia. Brand names such as Pepsi don’t produce distinctive clusters. A word like mouse leads to 5 different clusters. Two of these clusters are related to computer mouse one thematically related to gaming, the other one more general to computer peripherals. The other 3 clusters are thematically focused on biology or pharmaceutical research. These clusters could be used to ask the users whether they want to refine their query if the degree of ambiguity exceeds a predefined threshold. The search engine could then ask: Do you mean mouse in the context of computers or in the context of biology / pharmaceutical research?
To sum up, word embeddings can give us at least some of the advantages of large language models to a much lower price, they can be integrated easily into traditional information retrieval systems, and their effect on search remains explainable. It makes a lot of sense to still use them at least as a transitional technology.
[1] The problem that queries and documents use different wording for the same concept.