Unstructured data in companies: Why it is the biggest challenge for GenAI
Almost every company has millions of unstructured files – spread across PDFs, Word documents, emails, presentations, images, CAD files, and website content. This data is mostly unstructured, with little or no consistently maintained metadata, from a wide variety of departments, spread across different systems. These files often contain important information that cannot be found or used directly.
What does this mean in concrete terms? Three typical examples from practice:
- Screenshots or scans of invoices: The information (date, amount, invoice number) is there – but as an image.
- Versions in file names such as "Presentation_Hanover Fair_V1_final_pptx": These contain valuable version or context information that cannot be read directly from the file content.
- Folder structures in the file system: These often indicate whether a document originates from a specific company department or belongs to a specific project, for example – but the information is contained in the path, not in the document itself.
These examples show that the information is available, but the company cannot use it due to its lack of overarching context and its diversity. This is exactly where intelligent enterprise search comes in. It transforms unstructured and technically diverse content into contextualized information that can be efficiently searched and processed.
The key: creating structure with AI-based enterprise search
Modern AI-based search systems such as iFinder combine classic information retrieval methods with AI to not only search unstructured data, but also enrich it intelligently and chat with the company's own information without distortion. In the process known as enrichment,
- content is extracted (e.g., from PDFs, images, scans),
- enriched with metadata (e.g., author, date, topic),
- and classified (e.g., category, document type, project reference).
Today, this is no longer done using complex manual pipelines, but rather via AI-supported processes with LLMs, multimodal and specialized extraction models.
A real-life example shows how powerful this effect is in practice: A customer submits 30,000 records of stock purchases as screenshots. An AI system recognizes the relevant values (date, price, number), extracts them, and makes them searchable and filterable.
The advantage: Companies do not have to prepare their data manually. The search software takes care of this – standardized, automated, without extra coding. This creates a structured database that recognizes correlations and serves as a reliable basis for generative AI.
Graphic: From data flood to answer: How enterprise search makes knowledge usable for AI
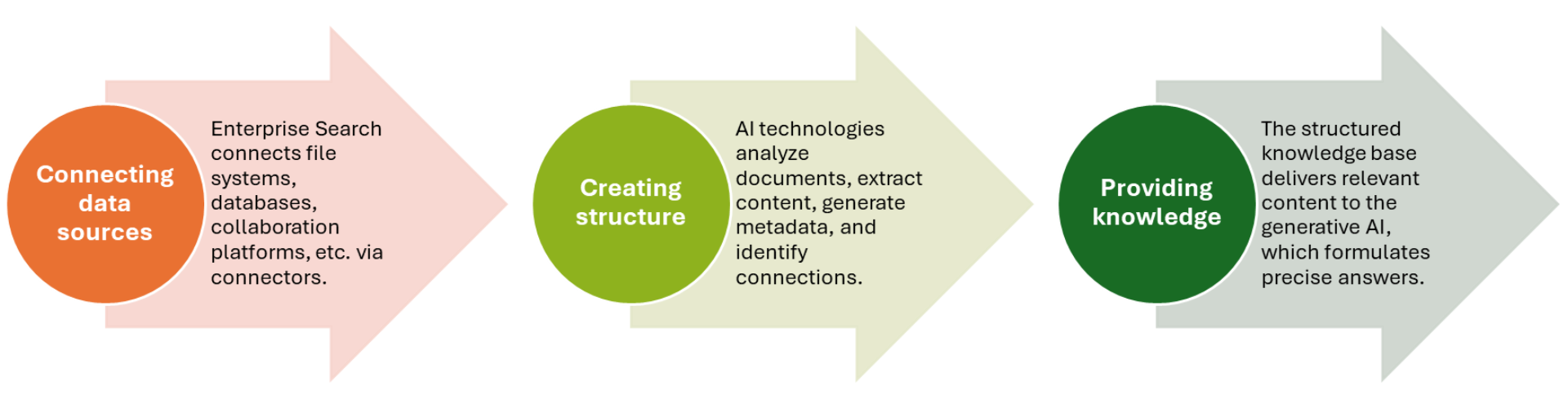
Without quality-assured information, AI remains blind
A common misconception is that you can throw "everything" into an AI system and expect magical answers. In practice, however, it has been shown that even the best generative AI cannot deliver reliable results if unstructured data is processed unprepared. The result can be "garbage in, garbage out."
Effective systems therefore rely on clever preprocessing: scattered data is turned into usable knowledge building blocks – quickly findable, contextualized, and searchable.
Conclusion: Structure is the basis for precise answers
Semantically structured and indexed content is easy to generate today. AI-based search software such as iFinder takes care of all the preparation and information retrieval and, in combination with the generative AI assistant iAssistant, provides a powerful tool that combines search and chatbot functions on a reliable database.






