Unstrukturierte Daten im Unternehmen: Warum sie die größte Herausforderung für GenAI sind
Nahezu jedes Unternehmen sitzt auf Millionen unstrukturierter Dateien – verteilt auf PDFs, Word-Dokumente, E-Mails, Präsentationen, Bilder, CAD-Dateien oder Webseiteninhalten. Diese Daten sind meist unstrukturiert, ohne oder bestenfalls mit dürftig konsistenten Metadaten, aus verschiedensten Fachbereichen, verteilt über verschiedene Systeme. Oft schlummern in diesen Dateien wichtige Informationen, die aber nicht direkt auffindbar oder nutzbar sind.
Was bedeutet das konkret? Drei typische Beispiele aus der Praxis:
- Screenshots oder Scans von Rechnungen: Die Informationen (Datum, Betrag, Rechnungsnummer) sind da – aber als Bild.
- Versionen in Dateinamen wie "Präsentation_Hannover Messe_V1_final_ pptx": Diese enthalten wertvolle Versions- oder Kontextinformationen, die nicht direkt aus dem Dateiinhalt auslesbar sind.
- Ordnerstrukturen im Filesystem: Diese geben oft an, ob ein Dokument z. B. aus einer bestimmten Unternehmensabteilung stammt oder zu einem bestimmten Projekt gehört – die Info steckt aber im Pfad, nicht im Dokument selbst.
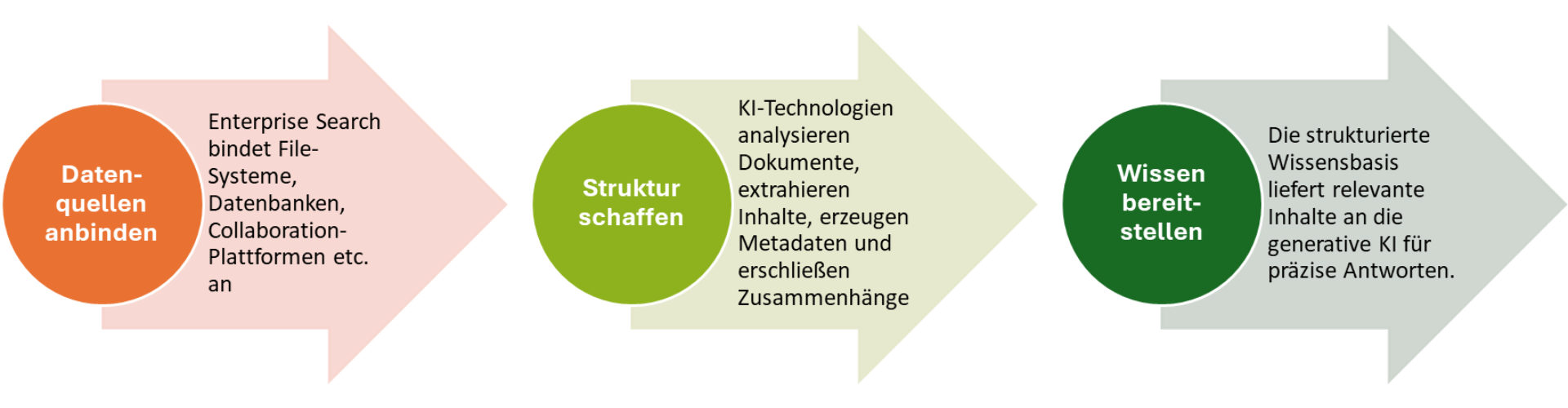
Diese Beispiele zeigen: Die Informationen sind vorhanden – aber das Unternehmen kann sie aufgrund ihrer fehlenden übergreifenden Kontexte und ihrer Vielfältigkeit nicht nutzen. Genau hier setzt intelligente Enterprise Search an. Sie verwandelt unstrukturierte und fachlich diverse Inhalte in kontextualisierte Informationen, die sich effizient durchsuchen und weiterverarbeiten lassen.
Der Schlüssel: Struktur schaffen durch KI-basierte Enterprise Search
Moderne KI-basierte Suchsysteme wie der iFinder kombinieren klassische Information-Retrieval-Methoden mit KI, um unstrukturierte Daten nicht nur zu durchsuchen, sondern auch intelligent anzureichern und mit den unternehmenseigenen Informationen verzerrungsfrei zu chatten. Bei dem sogenannten Enrichment werden
- Inhalte extrahiert (z. B. aus PDFs, Bildern, Scans),
- mit Metadaten angereichert (z. B. Autor, Datum, Thema),
- und klassifiziert (z. B. Kategorie, Dokumenttyp, Projektbezug).
Dies geschieht heute nicht mehr durch aufwändige manuelle Pipelines, sondern über KI-gestützte Prozesse mit LLMs, multimodalen und spezialisierten Extraktionsmodellen.
Wie stark dieser Effekt in der Praxis ist, zeigt ein reales Beispiel: Ein Kunde reicht 30.000 Nachweise über Aktienkäufe als Screenshots ein. Ein KI-System erkennt die relevanten Werte (Datum, Preis, Anzahl), extrahiert sie, macht sie durchsuchbar und filterbar.
Der Vorteil: Unternehmen müssen ihre Daten nicht manuell aufbereiten. Die Suchsoftware übernimmt das – standardisiert, automatisiert, ohne Extra-Coding. So entsteht eine strukturierte Datenbasis, die Zusammenhänge erkennt und als verlässliche Grundlage für generative KI dient.
Grafik: Von der Datenflut zur Antwort: Wie Enterprise Search Wissen für KI nutzbar macht
Ohne kuratierte Informationen bleibt die KI blind
Ein verbreitetes Missverständnis: Man wirft „alles“ in ein KI-System und erwartet magische Antworten. In der Praxis zeigt sich jedoch: Wenn unstrukturierte Daten unvorbereitet verarbeitet werden, liefert auch die beste generative KI keine zuverlässigen Ergebnisse. „Garbage in, garbage out“ kann hier das Resultat sein.
Effektive Systeme setzen deshalb auf clevere Vorverarbeitung: Aus verstreuten Daten werden verwertbare Wissensbausteine – schnell auffindbar, kontextualisiert und durchsuchbar.
Fazit: Struktur ist die Basis für präzise Antworten
Semantisch strukturierte und erschlossene Inhalte lassen sich heute einfach erzeugen. KI-basierte Suchsoftware wie der iFinder übernimmt die gesamte Aufbereitung und das Information Retrieval und liefert in Kombination mit dem generativen KI-Assistenten iAssistant ein leistungsstarkes Tool, das Suche und Chatbot-Funktion auf verlässlicher Datenbasis vereint.






