Efforts to adapt language for gender-appropriate expression have produced a lot of new word formations in German. Here are some of the most common spellings:

The phenomenon of such gendered expressions brings some challenges for text processing and search:
- some stems of the newly formed expressions differ from their corresponding common base forms and sometimes have different meanings: Kolleg in Kolleg:innen does not equal Kollege.
- the affixes "-in" and "-innen" also correspond to stand alone German words and can thus be found incorrectly as a result of search queries.
In this blog post, we show how the iFinder software addresses these challenges.
In our solution for the search tasks, we strive not only to provide a set of matching documents to a search query, but also to correctly interpret the intention of each search query. For this purpose, texts are analyzed and normalized in various ways. One of the many techniques used for this is lemmatization: it is determined which of the various word forms can be traced back to a base form. Thus, a good lemmatizer recognizes that words such as Mitarbeiter (engl. employee), Mitarbeiterin, Mitarbeiters, Mitarbeiterinnen have a common base form. And the search queries with all these forms should produce possibly the same set of hits during a standard search. The exact search offers the possibility to search specifically for one of these word forms. Here is an example: When searching for "Mitarbeiterin", only hits containing "Mitarbeiterin" are returned. Hits with "Mitarbeiter", "Mitarbeiterinnen" etc. will not be in the result list of the exact search.
Even before the lemmatizer can analyze the word forms, the boundaries of individual words should be correctly recognized. The spelling of the new gender expressions poses another challenge here, since it does not correspond to the word spelling conventions of the German language. A wide variety of characters occur in the middle of words, most of which are rightly seen and interpreted as word separators. Therefore, the first step is to recognize the correct word boundaries for many spellings of gender expressions. In the next step, the recognized word forms are normalized for the standard search, in order to determine their correct base forms afterwards. These steps are naturally applied during the indexing and during the search. Thus, we arrive at the same hit sets for different queries while performing standard search. Here are hit numbers, given in thousands, that we get from a test system of iFinder, comparing standard search versus exact search:
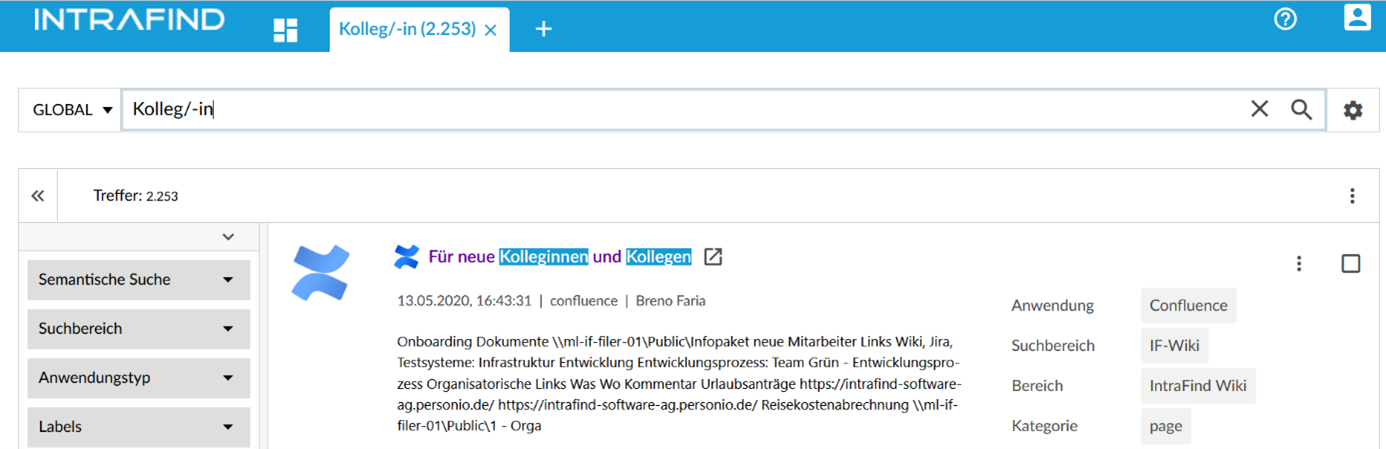
The corresponding hits are also correctly highlighted, here is a small illustration:

or by the example „Kolleg-/in“:
and
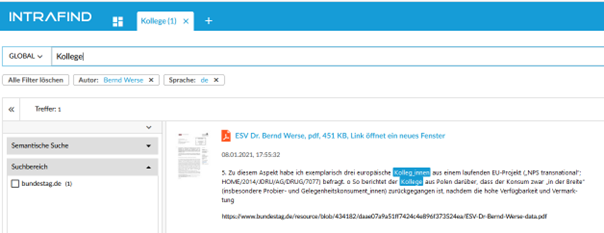
Conclusion: Our solution iFinder ensures the findability of all common spellings of the new expressions. The possible misspellings due to affixes (in, innen) are significantly reduced.
Linguistically, other phenomena occur in other languages with regard to gender spelling. In English, for example, we don’t register as many new word forms, but a change in language usage. There, terms that refer to a man or a woman have simply been replaced by neutral expressions, e.g.:
fireman = firefighter
policeman = policeofficer
stewardess = flight attendant
In this case, iFinder uses a supplementary thesaurus function to ensure that corresponding synonyms are found.