
26.08.2015 | Blog Language Identification and Language Chunking
Identifying the language of a given text is a crucial preprocessing step for almost all text analysis methods. It is considered as a solved problem since more than 20 years. Available solutions build on the simple observation that for all languages typical letter sequences (letter n-grams) exist, that occur significantly more frequent in this language than in other languages. Even the frequency of individual letters differs significantly for European languages. The letter “e” is the most frequent single letter in most European languages, but for Polish the most frequent letter is “a”.

Figure 1: All letter n-grams of length 1 (unigram) to 4 (tetra gram) for "TEXT" with "_" as marker for start and end of text
Tika: Cavnar & Trenkle Approach
All existing solutions for language identification build some kind of letter n-gram model or profile for every language, which is then compared with the letter n-gram profile of the text that is analyzed. A very simple approach was described in [C&T94] and is still used by the Apache Tika language identifier. The profiles generated in their approach simply consist of the most frequent letter n-grams sorted according to their frequency and the comparison of text and language profiles is based on a heuristic measure which compares the rank of letter n-grams in both profiles:
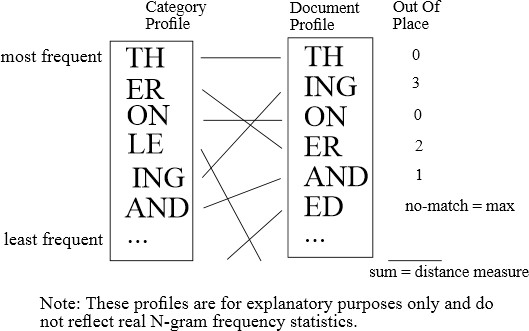
Figure 2: Apache Tika / C&T94 Approach
As stated already in the beginning, language identification is considered a solved problem. For text that is longer than 100 characters, there are methods that identify the correct language with an accuracy of 99%. This means that we might still have ten thousand incorrectly classified documents in a 1 million documents collection. So there is definitely still room for improvement. Furthermore, accuracy of established approaches drops considerably if we consider shorter text chunks like tweets or search engine queries.
Since there is an increasing need for accurate language identification for short text, research activity in the field has increased during the last 5 years. At IntraFind we recently also decided to take a closer look at language identification. I think we got some interesting findings.
First we tested the simple Apache Tika implementation on the LIGA benchmark (language identifier benchmark on twitter data, see [T&P11]). We got an accuracy of 97.7%, much better than the 93% reported by [T&P11] with the Tika implementation. In contrast to [T&P11] we used our own training data set which is much bigger than the data set used by [T&P11] (they used cross validation on the benchmark itself). Our result is even slightly better than the result achieved by [T&P11] with their own very sophisticated new approach. This shows that using big sets of training data is important.
Google: Naïve Bayes
Established approaches for language identification such as the Naïve Bayes approaches used by the current Google implementations (e.g. the Chromium Language Detector used in the Chrome Browser) use a fixed n-gram length. Usually an n-gram length of 4 is used for European languages and a length of 2 is used for Chinese or Japanese. For a comparison see [McC11].
Latest Developments
Latest developments that try to improve language identification accuracy consider longer n-grams. This is motivated by the fact, that languages are not only characterized by typical short letter n-grams. Humans recognize languages because they know frequent words and those words are usually longer than 4 letters.
We tested a language identifier based simply on counting the number of matching words for each language using our morphological lexica and achieved an accuracy of 99.4% on the LIGA benchmark. This is better than the best result reported on that benchmark (as far as we know) and it confirms the idea that a fixed short n-gram length is incompatible with further improvements in language identification. However, language identification is considered as a preprocessing step which should be very fast. Lexicon lookup is not a practical solution, especially since good morphological lexica might not be available for all languages.
Markov Chain
Standard Naïve Bayes n-gram approaches do not allow to consider variable-length n-grams in a straightforward way. We therefore decided to use a Markov Chain model [Dun94], which actually allows to use variable-length n-grams by using a back-off approach for estimating letter n-gram probabilities. With our current implementation we achieve an accuracy of 99.2% on the LIGA benchmark, which is identical to the best published result that we know.
Furthermore our Java-based implementation is very fast. On a current notebook processor with one thread we achieve a throughput of 5.5 MB/sec (counting each character as one byte), which is approximately 5 times faster than the Apache Tika implementation and comparable to the performance of the fastest existing language identifier (Google’s Chromium language detector).
Language identification is not the only goal we wanted to achieve with our new language identifier. It can be used to automatically identify chunks with the same language within a given text and since we have a high accuracy for short text we are even able to identify short chunks (see figure 3).
German Tweet: “Ich mag den Song la vie en rose sehr gerne.”
Chunk 1:Ich mag den Song
language: de
Chunk 2:la vie en rose
language: fr
Chunk 3:sehr gerne
language: de
Fig 3: Language Chunking Example
Bibliography:
"Gram-Based Text Categorization", William B. Cavnar , John M. Trenkle, In Proceedings of SDAIR-94, 3rd Annual Symposium on Document Analysis and Information Retrieval, 1994
[T&P11] “Graph-based n-gram language identification on short texts.”, Erik Tromp and Mykola Pechenizkiy, In Proceedings of Benelearn, The Hague, Netherlands, 2011
[Dun94] “Statistical Identification of Language”, Ted Dunning, Technical Report New Mexico State University, 1994
[McC11] “Accuracy and performance of Google's Compact Language Detector”, Michael McCandless Blog: http://blog.mikemccandless.com/2011/10/accuracy-and-performance-of-googles.html
The author
Dr. Christoph Goller


