Bild


Suchmaschinen sind ein fester Bestandteil unseres täglichen Lebens – wie selbstverständlich nutzen wir das kleine Textfeld im Privaten oder Beruflichen. Denn in Zeiten der überbordenden Informationsflut, ist eine Suchmaschine unentbehrlich, um im Meer der digitalen Informationen zu navigieren. Aber was verbirgt sich hinter dem unscheinbaren Textfeld, und wie findet eine Suchmaschine die Informationen, nach denen wir suchen? Genau dieser Frage möchten wir in unserer neuen Blog-Serie nachgehen und einen Blick in den Maschinenraum einer Suchmaschine werfen, um mehr über die Technologien dahinter zu erfahren.
In unserem ersten Blog-Post gehen wir auf das Thema der „natürlich sprachlichen Verarbeitung“, also Natural Language Processing, kurz NLP ein. Denn ohne die Verarbeitung von natürlicher Sprache ist eine Suchmaschine nicht in der Lage, Informationen zu verarbeiten, um passende Antworten auf unsere Fragen zu liefern. So ist die Sprache der Schlüssel zur Welt, aber erst, wenn uns Computer verstehen, können wir die Welt der digitalen Informationen komplett erschließen.
Die Geschichte der Verarbeitung natürlicher Sprache begann in den 1950er-Jahren, doch spätestens, mit der Einführung von Apples Siri im Jahr 2011, hat das Thema den breiten Kreis der Öffentlichkeit erreicht. Aber erst seit wenigen Jahren hat NLP die von Ihren Erfinder:innen prophezeite Revolution eingeläutet und die Art und Weise verändert, wie Menschen und Computer kommunizieren.
Die Revolution ist dringend notwendig in unserer wissensbasierten Gesellschaft mit einem explosionsartigen Wachstum an Informationen. Denn wir müssen die immer drängende Frage beantworten: Wie bewältigen wir die Flut an Informationen? Wie können wir Informationen effizient organisieren, strukturieren und ordnen? Eine Antwort auf diese Fragen liefert NLP, also die Verarbeitung von natürlicher Sprache durch Computer. Durch eine Vielzahl von KI-Modellen kann Wissen extrahiert, aufgezeichnet, dargestellt und in elektronischer Form formuliert und verarbeitet werden. Dies ermöglicht nicht nur die direkte Nutzung, sondern auch die Gewinnung von neuen Erkenntnissen, um unser Wissen zu erweitern.
Die verschiedenen Konzepte der natürlichen Sprachverarbeitung, die sich mit der Verarbeitung-, dem Verstehen- und der Erzeugung natürlicher Sprache beschäftigen, sind zwar miteinander verwandt, aber dennoch unterschiedlich:
Natural Language Processing (NLP), kommt aus der Computerlinguistik und verwendet Methoden aus verschiedenen Disziplinen wie Informatik, künstliche Intelligenz, Linguistik und Data Science. Das Ziel ist, Computer in die Lage zu versetzen, menschliche Sprache in schriftlicher und mündlicher Form zu verarbeiten.
Natural Language Understanding (NLU), ist ein Teilbereich von NLP, und konzentriert sich auf die Ermittlung der grammatikalischen Struktur und Bedeutung eines Textes. Das ist wichtig, wenn es etwa um die korrekte Identifikation von Subjekt und Objekt, die Erkennung eines Vorgangs, der Relation einer Frage oder die richtige Zuordnung von Pronomen geht. So kann eine Maschine die beabsichtigte Bedeutung eines Textes verstehen, Suchmaschinen Fragen beantworten oder Intelligent Document Processing Dokumente analysieren, klassifizieren und verteilen.
Natural Language Generation (NLG), ist ein weiterer Teilbereich von NLP. Während sich NLU auf das Leseverständnis von Computern konzentriert, befähigt NLG Computer dazu, natürliche Sprache zu erzeugen. NLG umfasst auch Funktionen zur Textzusammenfassung, die aus Dokumenten Zusammenfassungen erstellen und dabei die Integrität der Informationen wahrt.
Der Einfachheit halber verwenden wir im folgenden Text weiterhin den Oberbegriff NLP.
Die menschliche Sprache ist kompliziert und der Prozess, Sprache zu verstehen, äußerst komplex. Deswegen ist es üblich, unterschiedliche NLP-Techniken zur Bewältigung verschiedener Herausforderungen anzuwenden und miteinander zu kombinieren. Dabei werden in mehreren Schritten menschliche Text- und Sprachdaten zerlegt, um Computer in die Lage zu versetzen, strukturierte Daten aus der natürlichen Sprache zu extrahieren, und zu verarbeiten.
In diesem Artikel möchten wir einen Überblick über die verschiedenen Techniken und Methoden zur Verarbeitung von natürlicher Sprache geben:
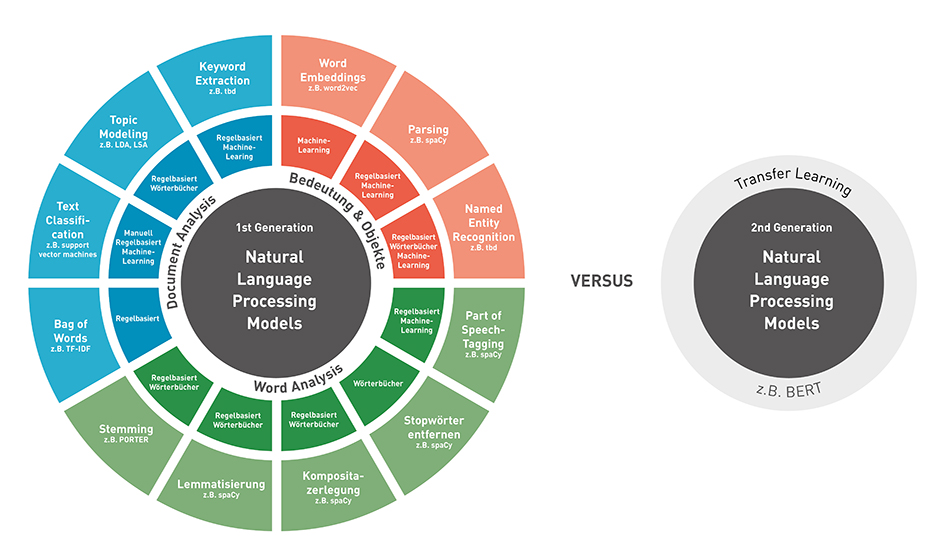
Dabei ist NLP gerade in Kombination mit Machine Learning ein weites Feld, das sich rasant weiterentwickelt und in Zukunft viele neue Ansätze hervorbringen wird.
Unter Tokenisierung versteht man, vereinfacht gesagt, die Aufteilung von Zeichenfolgen, etwa einer Phrase eines Satzes, eines Absatzes, eines oder mehrerer Textdokumente in kleinere Einheiten. Jede dieser kleineren Einheiten wird als Token bezeichnet und kann alles Mögliche sein – ein Wort, ein Teilwort oder sogar ein Zeichen.
Durch die Analyse der im Text enthaltenen Wörter kann die Bedeutung des Textes besser interpretiert werden. Mit einer Liste von Wörtern können statistische Werkzeuge und Methoden angewendet werden, um weitere Einblicke in den Text zu bekommen. Wie etwas, das Bag of Words Modell, um die Häufigkeit von Wörtern in einem Dokument zu bestimmen und zu bewerten.
Hier ein kleines Beispiel aus Star Wars mit Zitaten von Han Solo und Luke Skywalker:
Ich weiß, Sie mögen mich, weil ich ein Schurke bin.
Ich bin Luke Skywalker. Ich bin hier, um Sie zu retten.

Obwohl das Trennen von Wörtern durch ein Satzzeichen recht einfach erscheint, reichen sie allein oft nicht aus, um eine korrekte Tokenisierung durchzuführen. Sie kann dazu führen, dass bestimmte Tokens falsch aufgespalten werden, wie Punkte bei Abkürzungen (z. B. Dr.) oder ein Ausrufezeichen in einem Künstlernamen (z. B. P!nk). Das kann auch bei der Verarbeitung von komplexen Begriffen z. B. in der Medizin, die viele Bindestriche, Klammern und andere Satzzeichen enthalten, problematisch werden.
In den Artikeln The Evolution of Tokenization in NLP — Byte Pair Encoding in NLP, Tokenization Algorithms in Natural Language Processing (NLP) und Word, Subword, and Character-Based Tokenization: Know the Difference findet Ihr noch mehr zum Thema.
Die Wörter, die vor der Verarbeitung einer natürlichen Sprache herausgefiltert werden, nennt man Stoppwörter. Dabei handelt es sich um häufig vorkommende Wörter (z. B. Artikel, Präpositionen, Pronomen, Konjunktionen usw.), die dem Text nicht viel Information hinzufügen. Beispiele für einige Stoppwörter im Deutschen sind „ich“ „sie“, „weil“, „und“, „ein“.

Das Problem beim Entfernen von Stoppwörtern ist, dass relevante Informationen verloren gehen können und dadurch der Kontext eines Satzes verändert wird. Würde Han Solo sagen: „Ich weiß, Sie mögen mich nicht, weil ich ein Schurke bin“ und wir würden das Stoppwort „nicht“ entfernen, bekommt der Satz einen ganz anderen Kontext. Das gleiche Problem entsteht z. B. auch bei einer Sentiment Analysis. Daher ist es wichtig, der Stoppwortliste je nach Zielsetzung zusätzliche Begriffe hinzuzufügen oder zu entfernen.
In dem Artikel Stop Words in NLP findet ihr noch weitere Informationen und Beispiele. Außerdem findet ihr in 22 new stopword languages - 54 in total einen Open-Source Service für Stoppwörter in 54 Sprachen.
In einigen Sprachen, vorwiegend im Deutschen, werden häufig mehre Worte zu einem einzelnen Wort zusammengesetzt – einem sogenannten Kompositum. In diesen Sprachen ist deshalb die Kompositazerlegung ein wichtiger Aspekt der Verarbeitung von natürlicher Sprache. Im Rahmen der Kompositazerlegung werden die zusammengesetzten Wörter wieder in ihre Bestandteile zerlegt, so z. B. der Bundesumweltminister in Bund, Umwelt und Minister.
Schließlich soll eine Suche nach „Bundesminister Umwelt“ auch den „Bundesumweltminister“ liefern, „Verein“ soll auch „Sportverein“ finden und „Bundestagswahl“ ist ein guter Treffer bei der Suche nach „Wahl“.
Die Worttrennung kann nicht allein mit algorithmischen Mitteln gelöst werden, da die natürliche Sprache viel zu unregelmäßig ist, wie bei Gründung (Grün-Dung), Versendung (Vers-Endung) oder Hausaufgabe (Hau-Sauf-Gabe). Um eine Wortgrenze zu erkennen, ist es nicht möglich, einfach nach bestimmten Buchstabenfolgen zu suchen. Daher sind Wörterbücher mit verfügbaren Wortteilen für eine sinnvolle Worttrennung unerlässlich.
Die Kompositazerlegung spielt in der Verarbeitung von Sprache eine wichtige Rolle, etwa im Zusammenspiel mit der Lemmatisierung und bei der Semantisch-Linguistischen Indexierung für bessere Suchergebnisse.
Beim Stemming werden durch Algorithmen Affixe (lexikalische Zusätze zum Wortstamm) entfernt. So werden z. B. Suffixe wie bei „geh-en“, Präfixe wie bei „be-gehen“ oder Zirkumfixe wie bei „ge-leit-et“ für den Verbstamm „leit-“ (wie bei „leit-en“) entfernt.
Wörter werden dadurch unabhängig von lexikalischen Zusätzen auf ihren Basisstamm reduziert - was bei vielen Anwendungen wie dem Clustering oder der Klassifizierung von Texten hilfreich ist. Suchmaschinen nutzen diese Techniken, um unabhängig von der Wortform bessere Ergebnisse zu erzielen. Ohne Stemming würden bei der Suche nach „Fisch“ keine Ergebnisse für „Fischer“ oder „Fischen“ angezeigt werden.
Der 1980 entwickelte Porter-Stemming-Algorithmus hat sich als Quasi-Standard für das Stemming englischer Texte etabliert. Für verschiedene Sprachen werden modifizierte Stemming-Algorithmen verwendet. Sie sind auf die jeweiligen Eigenheiten und grammatikalischen Merkmale der Sprachen optimiert.
Allerdings kann Stemming auch zu unerwünschten Ergebnissen führen. Beim Overstemming werden zu viele Zeichen abgeschnitten. Was zur Folge hat, dass Wörter mit unterschiedlichen Bedeutungen auf dieselbe Form reduziert werden.
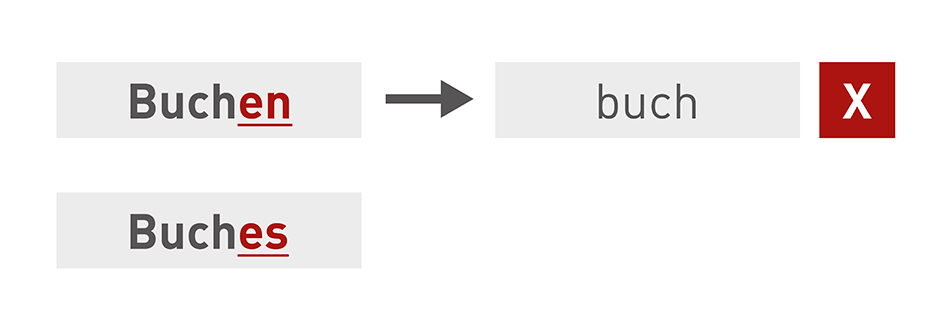
Beim Understemming werden zu wenig Zeichen abgeschnitten oder unterschiedliche Wortformen mit der gleichen Stammform werden wie unterschiedliche Wörter behandelt.
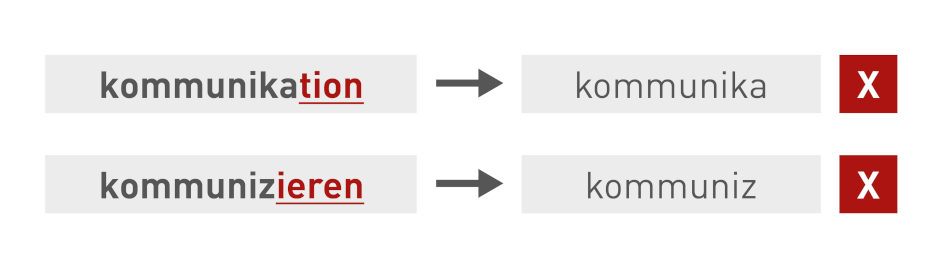
Stemming kann nicht auf alle Sprachen angewendet werden. Chinesisch kann beispielsweise nicht mit einem Stemmer bearbeitet werden, aber die indoeuropäischen Sprachen eignen sich mehr oder weniger gut dazu.
Auch wenn Stemming ernsthafte Einschränkungen hat, ist es einfach zu bedienen und läuft extrem performant (es werden nur einfache Operationen an einer Zeichenkette durchgeführt). Wenn Geschwindigkeit und Leistung im NLP-Modell wichtig sind, dann ist Stemming und Lemmatisierung sicherlich der richtige Weg.
Für alle, die sich mit Besonderheiten des Stemming tiefer beschäftigen möchten, bietet der Artikel NLP: A quick guide to Stemming einen guten Einstieg und einige anschauliche Beispiele.
Die Lemmatisierung nutzt Wörterbücher (lexikalisches Wissen), in denen der Algorithmus Wörter nachschlagen kann, um sie in ihre Wörterbuchform (bekannt als Lemma) aufzulösen. So ist es unter anderem möglich, den Wortstamm unregelmäßiger Verben oder andere nicht auf den ersten Blick erkennbare Abhängigkeiten zu einem Wortstamm zu identifizieren. So wird ein Wort auf seine Grundform reduziert und verschiedene Formen desselben Wortes zusammengefasst.
Zur Verdeutlichung: Mit reinem Stemming lässt sich das Wort „besser“ nicht auf den Wortstamm „gut“ reduzieren, oder Verben in der Vergangenheitsform in die Gegenwartsform umwandeln (z. B. "ging" in "gehen“). Die Lemmatisierung schafft dies aufgrund des lexikalischen Wissens problemlos. Auf diese Weise kann ein NLP-Modell lernen, dass alle Wörter ähnlich sind und in einem ähnlichen Kontext verwendet werden.
Die Lemmatisierung berücksichtigt auch den Kontext eines Wortes, um Probleme wie die Disambiguierung zu lösen. Durch die Angabe eines Part-of-Speech-Parameters für ein Wort (z. B. ob es sich um ein Substantiv oder ein Verb handelt) ist es möglich, die Rolle dieses Wortes im Satz zu erkennen und die Disambiguierung zu beseitigen. Wie das Wort „Spiel“ als Verb: „Sie spielen im Garten“; oder als Substantiv: „Sie gehen zu einem Spiel“.
Obwohl die Lemmatisierung eng mit dem Stemming-Verfahren verwandt zu sein scheint, verwendet sie einen anderen Ansatz, um die Stammformen von Wörtern zu identifizieren. Eine gute Einführung in das Thema liefert der Artikel State-of-the-art Multilingual Lemmatization.
Beim Part of Speech-Tagging (POS), auch grammatikalisches Tagging genannt, wird die Wortart eines bestimmten Wortes oder Textteils auf der Grundlage seiner Verwendung und seines Kontexts bestimmt.

Im Beispiel wird durch POS jedes Wort mit einem Wortart-Tag versehen, das seine Funktion definiert. Hier hat Peter ein PROPN-Tag, was bedeutet, dass es ein Eigenname ist. Außerdem gehören "hat" und "gekauft" zum Verb, was bedeutet, dass es sich um Handlungen handelt. Der Laptop und der Apple Store sind die Substantive.
Die POS-Tags können für eine Vielzahl von NLP-Aufgaben verwendet werden und sind äußerst nützlich, da sie linguistische Informationen liefern, wie ein Wort in einer Phrase, einem Satz oder einem Dokument verwendet wird. POS ist besonders nützlich, um die Bedeutung von Wörtern zu unterscheiden. So kann etwa unterschieden werden, auf welche Art das Wort „spielen“ verwendet wird: als Verb „Sie spielen am Samstag“ oder als Substantiv „Es wird ein großes Spiel werden.“
Bag of Words ist ein häufig verwendetes Modell, um alle Wörter in einem Satz zu zählen und wird häufig von Suchmaschinen und für viele weitere NLP-Aufgaben wie Textklassifikation verwendet. Im Grunde wird eine Häufigkeitsmatrix für den Satz oder das Dokument erstellt. Wobei Grammatik und Wortreihenfolge nicht berücksichtigt werden. Diese Worthäufigkeiten oder -vorkommen werden dann als Merkmale für das Training von Klassifikationen oder zum Taggen eines Dokuments verwendet.
Hier wieder unser Star Wars Beispiel:

Allerdings hat dieser Ansatz auch mehrere Nachteile, wie das Fehlen einer Bewertung von Bedeutung und Kontext. Oder die Tatsache, dass Stoppwörter (wie „es“ oder „ein“) die Analyse beeinträchtigen und manche Wörter nicht adäquat gewichtet werden (“Schurke“ wird weniger gewichtet als das Wort „ich“).
Ein Ansatz, um dieses Problem zu lösen, besteht darin, Wörter danach zu gewichten, wie häufig sie in allen Texten vorkommen und nicht nur in einem Dokument. Dieser Bewertungsansatz wird als "Term Frequency – Inverse Document Frequency" (TF-IDF) bezeichnet und verbessert die Ergebnisse durch Gewichtung.
Durch TF-IDF werden häufige Begriffe im Text "belohnt" (wie das Wort „ich“ in unserem Beispiel), aber sie werden auch "bestraft", wenn sie in anderen Texten ebenfalls häufig vorkommen. Im Gegensatz dazu werden bei dieser Methode Begriffe, die nur selten in allen Texten vorkommen, hervorgehoben, wie das Wort „retten“. Dennoch hat dieser Ansatz weder einen Kontext noch eine Semantik.
An Introduction to Bag-of-Words in NLP und Quick Introduction to Bag-of-Words (BoW) and TF-IDF for Creating Features from Text bieten eine gute Einführung und viele weitere Beispiele.
Um die häufigsten Schlüsselwörter (Keywords) aus einem Text zu extrahieren, werden meist verschiedene NLP-Verfahren miteinander kombiniert. Keywords sind oft der erste Schritt, um Themen und Themengruppen zu finden, die ein Dokument am genauesten beschreiben, um anschließend verschiedene Algorithmen für maschinelles Lernen anzuwenden und die Themen weiter zu untersuchen.
Zunächst werden die Texte durch Tokenization in einzelne Wörter zerlegt, Stoppwörter gefiltert, Komposita zerlegt, Stemming & Lemmatisierung angewendet, um anschließend mit „Bag of Words“ die Häufigkeit der Begriffe im Dokument zu ermitteln. Abschließend werden die Begriffe durch TF-IDF gewichtet – Voilà, fertig ist die Liste mit den wichtigsten Keywords. Wie das funktioniert, ist im Artikel Automated Keyword Extraction from Articles using NLP ausführlich beschrieben.
Moderne Varianten setzen mehr und mehr auf maschinelles Lernen, um relevante Schlüsselwörter in einem Dokument zu identifizieren. Manche Verfahren nutzten POS-Tagging kombiniert mit Heuristiken, um Wörter oder Phrasen auf Grundlage der Häufigkeit des Auftretens zu erstellen. Aber es gibt noch eine ganze Reihe von weiteren Möglichkeiten, wie in dem Artikel 10 Popular Keyword Extraction Algorithms in Natural Language Processing beschrieben.
Text classification, auch Topic classification, text categorization, oder document categorization bezeichnet, ist der Prozess Texte in bestimmte vordefinierte Kategorien zu klassifizieren. Es gibt viele Ansätze zur automatischen Textklassifizierung, die jedoch alle unter die folgenden vier Kategorien fallen: manuell, regelbasiert, maschinell und hybrid.
Manuell
Bei der manuellen Textklassifizierung werden Texte von Menschen interpretiert und kategorisiert. Diese Methode kann gute Ergebnisse liefern, ist aber zeitaufwendig und teuer.
Regelbasiert
Beim regelbasierten Modell werden Texte mithilfe einer Reihe von linguistischen Regeln kategorisiert. Texte, in denen die Wörter „Luke Skywalker“ und „Han Solo“ vorkommen, würden in die Kategorie „Star Wars“ eingeordnet. Auch hier ist das handwerkliche Geschick von Sprachwissenschaftler:innen gefragt, um die linguistischen Regeln zu definieren. Der Vorteil von regelbasierten Modellen ist: Sie sind einfach zu verstehen und können mit der Zeit erweitert werden. Allerdings hat dieser Ansatz auch eine Reihe von Nachteilen: Sie sind anspruchsvoll in der Umsetzung und es braucht viele Analysen und Tests, um sie zu erstellen und zu pflegen.
Maschinell
Die maschinelle Variante klassifiziert Texte auf der Grundlage von gelernten Machine-Learning-Modellen. Wie bei NER handelt es sich hier um ein überwachtes Lernen, bei dem Machine-Learning-Modelle auf der Basis von vorklassifizierten Trainingsdaten trainiert werden. Hier gibt es eine Reihe von unterschiedliche Methoden, die angewendet werden können, Naive Bayes, Support Vector Machines oder Deep Learning basierte Verfahren. Die Herausforderung bei der Textklassifizierung besteht darin, die Kategorisierung aus einer Sammlung von Beispielen für jede dieser Kategorien zu "lernen", um Kategorien für neue Texte vorherzusagen.
Hybrid
Der vierte Ansatz zur Textklassifizierung ist der hybride Ansatz. Hybride Systeme kombinieren das maschinelle mit einem regelbasierten System. Diese hybriden Systeme können leicht feinabgestimmt werden, indem spezifische Regeln für komplexe Klassifikationen erstellt werden, die vom Machine-Learning-Modell nicht korrekt erkannt wurden.
Bei der Verarbeitung natürlicher Sprache werden viele Ansätze des „supervised learning“ verwendet. Wie bei der Erkennung von Entitäten oder der Klassifikation von Texten, bei denen trainierte Machine-Learning-Modelle Entitäten erkennen oder Texte klassifizieren. Es gibt aber auch „unsupervised learning“, bei dem nur die Texte vorhanden sind und etwa Kategorien auf der Grundlage von Ähnlichkeiten gefunden werden.
Topic-Modeling ist eine Technik des „unsupervised learning“ und ist in der Lage, verborgene semantische Strukturen in einem Dokument zu erfassen. Denn alle Topic-Models basieren auf der gleichen Annahme: jedes Dokument besteht aus einer Mischung von Themen und ein Thema besteht aus einer Reihe von Wörtern. Das heißt, wenn diese versteckten Themen erkannt werden, können wir den Sinn des Textes erschließen.
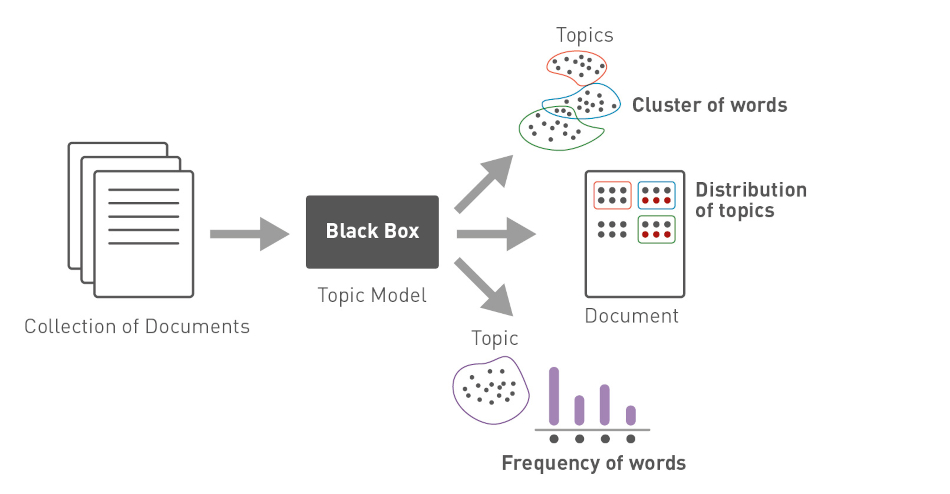
Um diese versteckten Themen zu erkennen, gibt es eine Reihe von verschiedenen Topic-Modeling Algorithmen wie Latent Dirichlet Allocation (LDA), Non-negative Matrix Factorization (NMF) oder Latent Semantic Analysis (LSA). So identifiziert etwa der LDA Algorithmus Gruppen von verwandten Wörtern, indem er jedem Wort ein zufälliges Thema zuweist. Der Algorithmus berechnet nun für jedes Wort die Wahrscheinlichkeit, ob es zu einem Thema passt und ordnet es bei hoher Wahrscheinlichkeit dem Thema zu. Das Ganze wird so lange wiederholt, bis sich die Zuordnung der Themen nicht mehr ändert.
Named Entity Recognition (NER) identifiziert benannte Entitäten in einem Text und ordnet sie vordefinierten Kategorien zu. Entitäten können Namen von Personen, Organisationen und Orten, Daten, Zeiten, Mengen, Geldwerte, Produktnamen, Prozentsätze, Ereignisse und mehr sein.
Für die Erkennung von Entitäten gibt es im Wesentlichen folgende Ansätze – regelbasierte Erkennung, Wörterbücher und maschinelles Lernen.
Wörterbücher
Ein wörterbuchbasierter Ansatz speichert so viele benannte Entitäten wie möglich in einer Liste, die als Gazetteer oder Lexikon bezeichnet wird. Dieser Ansatz ist recht simpel, da die einzige Aufgabe darin besteht, Entitäten einer Liste auf einen Text abzubilden. Außerdem können die Listen aus einer Datenbank (z. B. Produktnamen oder Artikelnummern), aus einem Text, dem Internet oder Wikipedia relativ einfach erstellt werden.
Wörterbücher haben aber auch Ihre Grenzen, etwas bei Erkennung von mehrdeutigen Begriffen. Zum Beispiel ist das Wort „Washington“ in „Präsident Washington“ – aufgrund des Kontexts eindeutig die Person „George Washington“. Wenn jedoch das Wort „Washington“ im Lexikon als Ort gefunden wird (wie in „Washington D.C.“), wird diese Entität als Ort klassifiziert. Diese Einschränkung zeigt, dass große Listen auch einige wichtige Entitäten übersehen können, aber mit geeigneten Techniken und Methoden ist dieser Nachteil behebbar.
Regelbasierte Erkennung
Für eine regelbasierte Erkennung werden umfangreiche linguistische Regeln und Heuristiken definiert, um bestimmte Entitäten in einem Text zu erkennen. So lässt sich etwa eine – zugegebenermaßen sehr simple – Regel definieren, um Personen zu erkennen: auf die Wörter „Frau“ oder „Herr“ folgen meist weitere Wörter für den Vor- und den Nachnamen, z. B. „Herr Peter Parker“.
In der Praxis sind die Regeln größtenteils recht komplex und stützen sich stark auf das Wissen von Sprachwissenschaftler:innen. Mit Wörterbüchern kombiniert können so auch Entitäten in Dokumenten mit wenig oder keinem Kontext erkannt werden (z. B. Excel Sheets mit Kundendaten). So erzielen Regeln in spezifischen Gebieten und festgelegten Typen von Entitäten hervorragende Ergebnisse – etwa, wenn für Machine Learning kein ausreichendes Trainingsmaterial zur Verfügung steht. Aber die Regeln lassen sich oft nur schwer auf andere Anwendungsgebiete transferieren – allerdings immer leichter als Machine Learning Modelle.
Machine Learning
Ein weiterer Ansatz ist die Nutzung von Machine Learning. Hier gibt es viele unterschiedliche Methoden, wie das Hidden Markov Model (HMM) oder Conditional Random Fields (CRF). Bei diesen Verfahren des überwachten Lernens müssen Entitäten manuell markiert und kategorisiert werden. Anschließend wird ein Machine-Learning-Modell trainiert, das anhand statistischer Zusammenhänge – beispielsweise im Satzbau – lernt, Entitäten vorherzusagen und in vordefinierte Klassen zu kategorisieren.
Der Nachteil ist, dass bei dieser Variante große Mengen annotierter Texte benötigt werden, um ein NER-Modell zu trainieren – die Hoffnung ist jedoch, dass bei Transfer Learning mit BERT weniger annotierte Daten gebraucht werden. Je größer der vorliegende Datensatz für das Training ist, desto besser funktioniert das damit erstellte Modell. Allerdings können im Gegensatz zu regelbasierten Systemen angelernte Modelle leichter für andere Anwendungsfälle genutzt werden.
Wichtig ist noch zu unterscheiden, dass das Erkennen des Typs einer Entität nicht dasselbe ist wie das Identifizieren einer bestimmten Entität. Zum Beispiel ist das Erkennen, dass Tom Hanks eine Person ist, nicht dasselbe wie zu erkennen, dass er auch ein Schauspieler ist.
Word Embedding ist ein Verfahren der Künstlichen Intelligenz, das erlaubt, die Ähnlichkeit zwischen Wörtern zu errechnen. Die Grundidee des Word Embedding besteht darin, dass der Kontext eines Wortes, durch seine benachbarten Wörter definiert wird – meist in einer Spanne von zwei Wörtern je Richtung. Die Umgebung eines Wortes definiert also die Semantik (Bedeutung) und die Syntax (Verwendung in der Satzstruktur) des Wortes.
Beim Word Embedding werden Wörter in einen Vektor umgewandelt. Dabei bestimmt die Länge des Vektors, wie viele Informationen über den Kontext eines Wortes gespeichert wird. Die Wörter, die häufig zusammen im gleichen Kontext vorkommen und in einer ähnlichen Bedeutung, haben auch näher beieinander liegende Vektoren.
So wird bei Word Embeddings die Bedeutung eines Wortes aus seinem Kontext heraus erschlossen – ganz im Gegenteil zum Bag of Words verfahren, wo Wörter lediglich gezählt werden.
Ein schönes Beispiel kommt von der Süddeutschen Zeitung. Sie analysierten mit dem word2vec Verfahren alle Reden im Parlament und der Algorithmus scheint auf diese Weise eigenständig die Kategorie "Weiblichkeit" gelernt zu haben. Die Vektoren Bundeskanzlerin und Frau haben dort hohe Werte für eine Ähnlichkeit.
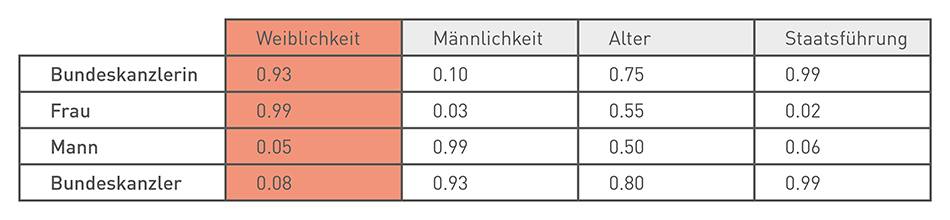
Der Embedding Projector der TensorFlow Library liefert ebenfalls anschauliche Beispiele. Hier scheint der Algorithmus gelernt zu haben, dass der Kongress, das Kapitol und das Monument zu Washington gehören.

Quelle: https://projector.tensorflow.org/
Der Nachteil von Word Embeddings ist, dass man einen sehr großen und möglichst „sauberen“ Text-Korpus benötigt, um eine sinnvolle Vektor-Repräsentation zu generieren. Auch werden identische Wörter mit unterschiedlichen Bedeutungen wie Golf“ (Auto, Sport oder Meeresbucht) oder „Schirm“ (Pilz-, Lampen- oder Regenschirm) nicht sauber unterstützt, da gleiche Wörter auf den gleichen Vektor abgebildet werden – unabhängig von ihrer Bedeutung.
Wer noch mehr über Word Embeddings erfahren möchte, kann der Frage in dem Artikel Why do we use word embeddings in NLP? nachgehen.
Beim POS Tagging werden nur die Wortarten markiert, und nicht die grammatikalische Beziehung der Worte innerhalb eines Satzes, um etwa Nominal- oder Verbalphrasen zu erkennen. Das wird durch das sogenannten „Parsing“ ermöglicht.
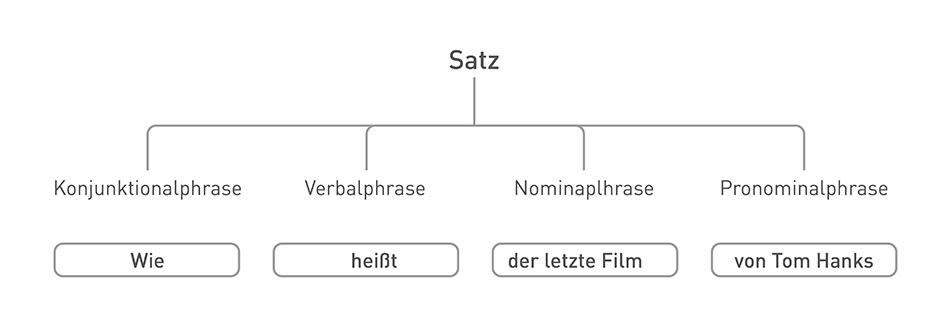
Nominal- oder Verbalphrasen sind Gruppen von Wörtern, die als Substantiv in einem Satz fungieren. In ähnlicher Weise ist eine Verbalphrase eine Gruppe von Wörtern, die in einem Satz als Verb fungiert. Hier ein paar Beispiele:
Phrasen zu erkennen ist wichtig, denn die Bedeutung eines Satzes lässt sich nur ableiten, wenn wir wissen, wie diese Wörter in einem Satz zusammengesetzt sind.
In anderen Fällen ist es nützlich, um die syntaktische Rolle (ist es etwa ein Subjekt oder Objekt) eines Wortes festzustellen und daraus semantische Informationen abzuleiten. Wie bei der Suche „Wie heißt der letzte Film von Tom Hanks“, wird die Verbalphrase (VP) „heißt“ verwendet, um die gewünschte Aktion zu spezifizieren; die Nominalphrase (NP) „der letzte Film“, um die Absicht der Aktion zu definieren; und die Pronominalphrase (PP) „von Tom Hanks“ als Subjekt für die Aktion.

Es gibt im Wesentlichen drei Methoden, um Sätze zu parsen, um Phrasen zu erkennen:
Das Syntaktische Parsing verwendet Regeln, um den Satz in Teilsätze zu zerlegen. Er wandelt den Satz in einen Baum um, dessen Blätter POS-Tags enthalten (die den Wörtern im Satz entsprechen). Der Aufbau des Baums gibt Aufschluss darüber, wie die Wörter zusammengefügt werden, um den Satz zu bilden.
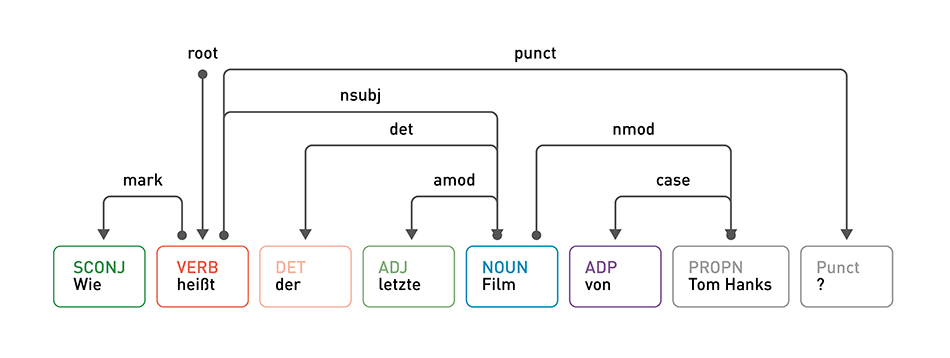
Das Dependency Parsing ordnet die Wörter eines Satzes nach ihrer Abhängigkeit. Eines der Wörter im Satz fungiert als Wurzel, und alle anderen Wörter sind über ihre Abhängigkeiten direkt oder indirekt mit dieser Wurzel verbunden.
Das Semantische Parsing zielt darauf ab, einen Satz in eine logische, formale Darstellung umzuwandeln, um sie anschließend besser verarbeiten zu können, wie:
Eine einfache arithmetische Aufgabe:
Eine Aufgabe zur Beantwortung einer Frage:
Eine Aufgabe für ein virtuelles Reisebüro:
Durch die Kombination der verschiedenen Parser wird die Struktur und Bedeutung von Sätzen erkannt. So können Texte zusammengefasst, klassifiziert, oder für Question-Answering, verwendet werden, wenn es darum geht, aus verschiedenen Informationen eine Antwort auf eine spezifische Frage zu erzeugen.
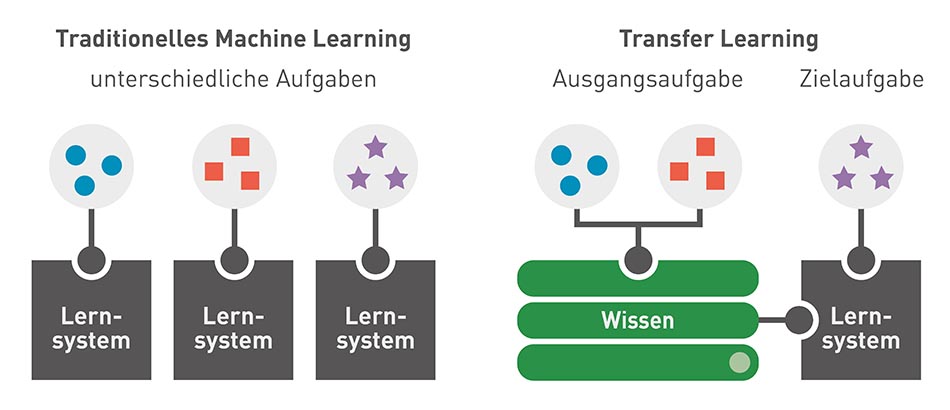
Transfer Learning hat eine neue Generation von vortrainierten Machine Learning Modellen zur Verarbeitung von natürlicher Sprache hervorgebracht. Im Gegensatz zu klassischen Maschine Learning Modellen, die eine große Menge an Trainingsdaten benötigen, wurden Transfer Learning Modelle wie GPT, BERT, oder ELMos bereits trainiert und können auf ein bestehendes Vorwissen aufbauen.
So können Transfer Learning Modelle schneller als klassische Machine Learning Modelle mit neuen Inhalten angepasst und auf neue Spezifikationen abgestimmt werden.
Ein populäres Transfer Learning Modell BERT wurden im Jahr 2017 erstmals von Google vorgestellt, und 2018 von Google als Open-Source-Software veröffentlicht. Seit dem Oktober 2019 nutzt Google BERT in der produktiven Suche, und ca. 10 Prozent aller Suchanfragen werden schätzungsweise mit der Hilfe von BERT beantwortet.
Ein wesentlicher Vorteil von Transfer-Learning-Modellen wie BERT ist die Fähigkeit, Kontext und Mehrdeutigkeit in der Sprache zu verstehen und Disambiguationen aufzulösen – was eine wichtige Weiterentwicklung zu Word Embeddings darstellt. BERT tut dies, indem es ein bestimmtes Wort im Zusammenhang mit allen anderen Wörtern in einem Satz verarbeitet, anstatt sie einzeln zu verarbeiten. Durch die Betrachtung aller umgebenden Wörter ermöglicht der Transformer dem BERT-Modell, den gesamten Kontext des Wortes zu verstehen.
Konkret heißt das, dass etwa das Wort "Bank" als a) Finanzinstitut oder b) Sitzbank in einem Park verwendet werden kann:
Ich zahle Geld in der Bank ein.
Ich sitze auf einer Bank.
Beim Word Embedding wird für das Wort „Bank“ ein Vektor erzeugt. BERT hingegen erzeugt zwei verschiedene Vektoren, da das Wort „Bank“ in zwei verschiedenen Kontexten verwendet wird. Ein Vektor ähnelt Wörtern wie Geld, Bargeld usw. Der andere Vektor würde Vektoren wie Park, Wiese, See usw. ähneln.
Das notwendige allgemeine „Sprachverständnis“ wurde BERT von Google auf der Basis umfangreicher Trainingsdaten (wie Wikipedia und dem Brown Corpus) beigebracht. Dieses Modell kann nun für verschiedene NLP-Aufgaben verwendet werden. Der Clou ist, dass BERT auf Gelerntem aufbaut und für viele verschiedene NLP Aufgaben schnell angepasst werden kann, z. B. für die Erkennung von Named Entities oder für die Implementierung einer Suche.
So können vortrainierte Transfer Learning Modelle direkt genutzt werden, um Sprache zu verarbeiten oder sie können für eine bestimmte Aufgabe, wie die Stimmungsanalyse und die Beantwortung von Fragen, mit eigenen Daten ergänzt werden.
Mehr über Transfer Learning und die unterschiedlichen Modelle erfahrt Ihr in dem Artikel „3 Pre-Trained Model Series to Use for NLP with Transfer Learning“.
Nicht weniger als 80 Prozent aller Informationen, die wir täglich konsumieren, sind unstrukturiert. Daher ist und wird NLP immer wichtiger, wenn es darum geht, Informationen zu verstehen und zu finden. NLP wird sich in den nächsten Jahren ständig weiterentwickeln und wir können davon ausgehen, dass es unser Leben in immer mehr Bereichen beeinflussen wird.




